
AWS EKS – Part 23 – Upgrade EKS Cluster and Worker Nodes
Kubernetes upgrade is divided into two main topics: upgrading the control plane and worker nodes. When it comes to AWS EKS, AWS provides various ways to upgrade Kubernetes clusters. In the case of the EKS control plane, it is entirely managed by AWS, and it gives a zero downtime model to upgrade the control plane. Regarding worker nodes, it depends on how you have deployed Kubernetes worker nodes. In this lesson, you will learn how to upgrade Kubernetes clusters, control pane and worker nodes in EKS based on the latest best practices to avoid or reduce downtime.
Follow our social media:
https://www.linkedin.com/in/ssbostan
https://www.linkedin.com/company/kubedemy
https://www.youtube.com/@kubedemy
Register for the FREE EKS Tutorial:
If you want to access the course materials, register from the following link:
Register for the FREE AWS EKS Black Belt Course
Kubernetes Control Plane upgrade process:
The Kubernetes control plane upgrade is the process of updating the core components responsible for managing and maintaining the Kubernetes cluster. These components include the kube-apiserver, etcd, kube-scheduler, kube-controller-manager, and cloud-controller-manager. On on-premises Kubernetes clusters, you must have at least three etcd instances and at least two instances of kube-apiserver kube-controller-manager kube-scheduler and cloud-controller-manager “if installed”. They must also be upgraded in the following order to avoid damage and problems.
- etcd cluster
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- cloud-controller-manager (if applicable)
You should update one version at once. For example, if you have a Kubernetes 1.25 cluster and want to upgrade to the latest version, you must:
- Update from 1.25 to 1.26
- Update from 1.26 to 1.27
- Update from 1.27 to 1.28
- Update from 1.28 to 1.29
Note: Worker nodes’ components can be three versions behind at most.
Note: Each Kubernetes version may deprecate old resources or even remove the deprecated ones. Before upgrading to a new version, check the documents or use the available tools to find deprecated and removed APIs and plan to migrate them.
How does EKS upgrade the Kubernetes control plane?
AWS EKS’s responsibility is to upgrade an old Kubernetes version to a new version without downtime. It upgrades all the explained components in a managed way without downtime. To achieve zero downtime, it deploys a new control plane behind the scenes and, after checking everything, removes the old one. Therefore, you may need up to 5 free IP addresses in the cluster subnets. On the other hand, you are responsible for taking care of deprecated/removed APIs and planning to migrate them.
Kubernetes Worker node upgrade process:
Upgrading Kubernetes worker nodes involves several steps to ensure minimal disruption to running workloads and maintain cluster stability. This process typically includes upgrading the operating system, packages, kubelet, container runtime, and kube-proxy. Moreover, before starting the upgrade procedure, you must cordon and drain nodes to migrate workloads to other available nodes to avoid service interruptions.
What is Kubernetes cordon?
kubectl cordon NODEThis command makes the node unschedulable to ignore it from the scheduling process. Right after cordoning the worker node, no Pods can be scheduled for that node.
What is Kubernetes drain?
kubectl drain NODE --ignore-daemonsets=trueThis command evicts all the running Pods on the node and forces them to be deployed into other available nodes. This command also leaves DaemonSet Pods on the node, as we don’t need to deploy them elsewhere. DaemonSet Pods are deployed into all Kubernetes nodes to provide a functionality like container networking, so it’s not a point to have two in the same worker node, even if possible.
System and components should be updated in the following order:
- OS packages (before OS upgrade)
- Operating system
- OS packages (after OS upgrade)
- kube-proxy
- kubelet
- Container runtime
In the end, you must uncordon the node to make it schedulable again. In addition, you can run node Conformance tests to validate it and verify its functionality.
How does EKS upgrade EKS worker nodes?
AWS EKS is responsible for doing all the steps explained above. It randomly selects worker nodes from the node group, “not more than maxUnavailable option”, cordons them to prevent scheduling on them, drains them to evict and deploy Pods to other nodes, and starts node upgrade by adding new nodes and removing the old ones.
Kubernetes complete upgrade procedure:
To upgrade the entire environment, Kubernetes control plane, Kubernetes worker nodes, addons, components, operators, operating system, etc. You must upgrade them in the order mentioned in detail below. You must never jump over the steps.
- Upgrade Kubernetes etcd instances (one by one):
- Backup
etcddatabase. - Update OS packages (pre-OS upgrade).
- Update Operating system.
- Update OS packages (post-OS upgrade).
- Update
etcdpackages. - Confirm the etcd cluster status.
- Backup
You should do the above loop for all etcd servers to upgrade.
Note: Instead of upgrading the current server, you can deploy a new upgraded one and replace it with an old one. This method is called Immutable upgrade.
EKS does all the steps automatically without user interactions.
- Upgrade Kubernetes control plane servers (one by one):
- Check for API deprecations and removals.
- Update OS packages (pre-OS upgrade).
- Update Operating system.
- Update OS packages (post-OS upgrade).
- Update kube-apiserver.
- Update kube-controller-manager.
- Update kube-scheduler.
- Update cloud-controller-manager (if applicable).
You should follow the above loop to upgrade all servers.
Important note: If there is a proxy between the kube-controller-manager, kube-scheduler, cloud-controller-manager and kube-apiserver servers, you must upgrade all the kube-apiserver instances first. Components must not be newer than the API server. Imagine you upgrade all components on the first control plane server from 1.28 to 1.29. Now, you have a server with all components upgraded to 1.29; if the kube-scheduler tries to reach the API server, as you have a proxy server to load balance requests between multiple API servers, there is a chance request being forwarded to an API Server with 1.28 version. What happens? A request from a kube-scheduler 1.29 goes to a kube-apiserver 1.28. It may break something. So, be cautious and plan everything carefully.
Note: Instead of upgrading the current server, you can deploy a new upgraded one and replace it with an old one. This method is called Immutable upgrade.
EKS does all the steps automatically without user interactions.
Kubernetes always makes room to avoid data corruption for API removals. It provides plenty of time between deprecating an API and its actual removal in new versions. So, you have plenty of time to convert an old resource to its new version. To avoid corruption, plan to convert the deprecated resources before actual removal.
Be an early bird to keep everything safe.
- Upgrade Kubernetes worker nodes (one/pool/zone by one):
- Backup local data like emptyDir (if applicable).
- Cordon the node to stop scheduling new Pods on that.
- Drain the node to evict the current Pods and deploy them elsewhere.
- Update OS packages (pre-OS upgrade).
- Update Operating system.
- Update OS packages (post-OS upgrade).
- Update kube-proxy.
- Update kubelet.
- Update Container runtime.
You should follow the above loop to upgrade all servers.
Note: Instead of upgrading the current server, you can deploy a new upgraded one and replace it with an old one. This method is called Immutable upgrade.
EKS does all the steps automatically without user interactions except backup.
- Upgrade Kubernetes addons/components/operators:
- Update node-critical components like the CNI plugin.
- Update cluster-critical components like operators providing CRDs.
- Update remaining things like logging and monitoring systems.
EKS Cluster and Worker Nodes upgrade procedure:
- Check for deprecated/removed API resources.
- Convert deprecated resources to new versions.
- Upgrade the EKS cluster control plane to the latest version.
- Upgrade managed node groups to the latest version.
- Upgrade managed node groups with custom launch templates.
- Investigate how worker nodes are upgraded.
Step 1 – Check Kubernetes deprecated APIs:
Various tools exist to find Kubernetes deprecated/removed APIs – Kube-no-trouble(kubent), Pluto, KubePug, mapkubeapis, Popeye, kdave, etc. Each one may provide different capabilities or may offer the same capabilities differently. From checking resources with OPA Rego policies to hard-coded rules, etc.
In this lesson, we want to work with Kube-no-trouble:
Kubent is a simple tool using OPA Rego policies to scan resources for deprecations/removals. It scans the entire cluster for every deprecated API that is due to be removed in the next version. It comes with built-in OPA policies.
https://github.com/doitintl/kube-no-trouble
# Download and install it from:
# https://github.com/doitintl/kube-no-trouble/releases
./kubentIt uses cluster and helm3 collectors by default. You can enable file collector instead.

As you can see, it shows the current cluster version, collects resources from cluster and helm charts, loads Rego rulesets and shows the deprecated resources.
Step 2 – Convert Kubernetes deprecated resources:
Kubernetes provides a kubectl plugin called convert, which helps us convert deprecated resources to their new versions. To install this kubectl plugin:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert"
install kubectl-convert /usr/local/bin/kubectl-convert
kubectl convert --helpTo convert manifests to their new API versions:
kubectl convert -f FILE.yaml
# Convert and apply it to API server.
kubectl convert -f . | kubectl apply -f -
kubectl convert test.yaml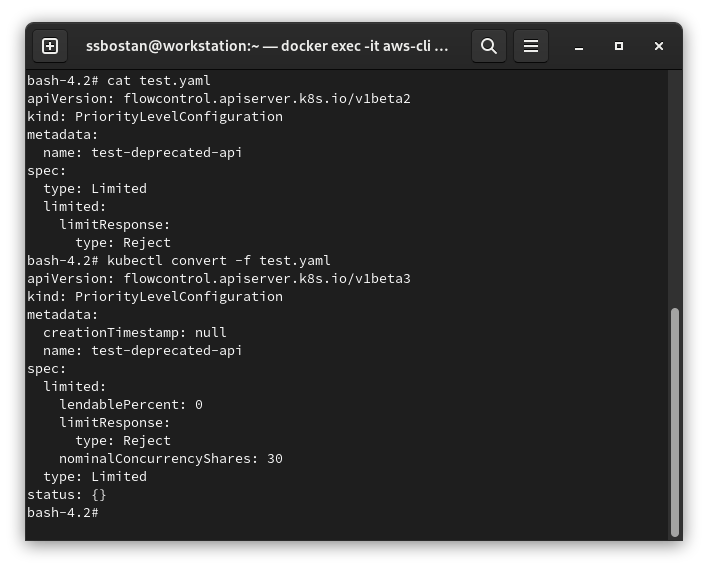
Note: If the API will be removed completely, like PodSecurityPolicy in Kubernetes 1.25, you must remove them before upgrading the cluster and plan to use alternatives. For example, instead of PSP, you can use PSA/PSS, OPA, Kyverno or Kubewarden.
Step 3 – Upgrade EKS cluster control plane:
Upgrading the EKS cluster control plane is super easy. You can upgrade your EKS cluster with one command. EKS will take care of the rest. To provide zero downtime upgrades, EKS deploys a new control plane first and after verifying its functionality, it removes the old one. Remember, As it deploys a new control plane in addition to the current one, you need up to 5 available IP addresses (depending on region) in cluster subnets.
To upgrade the control plane, run the following command:
aws eks update-cluster-version \
--name kubedemy \
--kubernetes-version 1.29It takes up to 10 minutes to update the cluster.
Step 4 – Upgrade EKS worker nodes:
Upgrading the EKS worker nodes is also quite easy when you use the managed node groups, “it’s also easy for custom launch templates and self-managed worker nodes but needs some additional steps explained in the next step”. Upgrading worker nodes can be done using the following command. Attention: If you don’t provide a Kubernetes version, it will update to the same version as the API server.
aws eks update-nodegroup-version \
--cluster-name kubedemy \
--nodegroup-name application-managed-workers-001 \
--kubernetes-version 1.29This command took 10 minutes to upgrade three worker nodes in a node group with three subnets. The exact process for upgrading three nodes in a node group with one subnet took 15 minutes. See the investigation step for more details.
Step 5 – Upgrade EKS using custom launch templates:
To upgrade EKS worker nodes deployed using a custom launch template, you must find the new AMI image for the new Kubernetes version, create a new template version and update the node group. To do so, execute the following commands:
aws ssm get-parameter \
--name /aws/service/eks/optimized-ami/1.29/amazon-linux-2/recommended/image_id \
--query "Parameter.Value" \
--output text
cat <<EOF > launch-template.json
{
"ImageId": "ami-0ba6a1ba476f5fc29",
"InstanceType": "t3.medium",
"UserData": "userdata.txt content",
"SecurityGroupIds": ["sg-09554af808fec6980"],
"KeyName": "kubedemy",
"PrivateDnsNameOptions": {
"EnableResourceNameDnsARecord": true
},
"Monitoring": {
"Enabled": true
}
}
EOF
aws ec2 create-launch-template-version \
--launch-template-name Kubedemy_EKS_Custom_Launch_Template \
--launch-template-data file://launch-template.json
# Upgrade node group to use version 2 of the launch template.
aws eks update-nodegroup-version \
--cluster-name kubedemy \
--nodegroup-name application-custom-launch-template-workers-001 \
--launch-template name=Kubedemy_EKS_Custom_Launch_Template,version=2To learn about launch templates in EKS, read the following article:
AWS EKS – Part 4 – Deploy worker nodes using custom launch templates
Step 6 – How EKS upgrades worker nodes:
Learning EKS node group upgrade behaviours helps you create a better plan for your upgrades to achieve zero downtime upgrades. Misunderstanding of this behaviour may lead to downtime. EKS upgrades worker nodes in four different phases:
Setup phase:
In this phase, a new launch template version will be created, and EKS will update the EC2 Auto Scaling Group to use the new version. Even if you use a custom launch template, EKS replicates it in its created launch template for that node group. It also determines the number of parallel upgrades based on maxUnavailable setting.
Scale-up phase:
EKS uses the immutable update method mentioned at the start of this article. So, it deploys new nodes and terminates the old ones. How it deploys and replaces the nodes matters, as misconfiguration may lead to significant costs and downtime. When EKS selects a node for the upgrade, it deploys a new node in the same availability zone as the original node. To meet this requirement and deploy to the same zone, it uses EC2 Availability Zone Rebalancing, which may need to deploy up to two instances (instead of one!). So, in the scale-up phase, the number of desired and maximum instances in EC2 Auto Scaling Group will be calculated based on the following algorithm:
# Increment desired and maximum instances by the larger of either:
--> up to twice the number of Availability Zones in which the Auto Scaling Group instances were deployed.
--> number of allowed maximum unavailable nodes (maxUnavailable).
##### Example 1 #####
maxUnavailable: 1
Number of Availability Zones: 3
Current desired instacnes: 3
Current maximum instances: 5
# Normal scenario (up to once): 1x3(AZs) > 1(maxUnavailable)
Scale-up desired instances: 6
Scale-up maximum instances: 8
# Worst scenario (up to twice): 2x3(AZs) > 1(maxUnavailable)
Scale-up desired instances: 9
Scale-up maximum instances: 11
##### Example 2 #####
maxUnavailable: 1
Number of Availability Zones: 1
Current desired instacnes: 3
Current maximum instances: 5
# Normal scenario (one instance per Availability Zone): 1x1(AZs) == 1(maxUnavailable)
Scale-up desired instances: 4
Scale-up maximum instances: 6
# Worst scenario (up to twice): 2x1(AZs) > 1(maxUnavailable)
Scale-up desired instances: 5
Scale-up maximum instances: 7After scaling up the nodes, at least one node per AZ should be deployed, and all nodes must be ready. When all nodes are ready, it cordons the old nodes to stop scheduling new Pods. It also marks them to be removed from external load balancers.
Upgrade phase:
In this phase, it starts a loop by randomly selecting worker nodes, “not more than maxUnavailable”, drains the nodes and deploys them somewhere else. After evicting every Pod, it continues cordoning the node for 60 seconds to be removed from the service controller and active nodes. Then, it sends a termination request to the Auto Scaling Group to terminate the drained nodes. This loop will be repeated continuously until all the nodes are drained, replaced and terminated.
Scale-down phase:
At this stage, it starts decreasing the number of desired and maximum by one until it reaches the original values. If the worst scenario happens, your Pods may be evicted more than once during the upgrade. If, during this process, you or the Cluster Autoscaler scale the node group, it uses the available nodes without waiting to remove the remaining nodes and start the scaling process.
EKS Node Group and update best practices:
- Create one node group per availability zone. This best practice helps you to reduce upgrading costs and downtime and increase stability. This method is also a best practice if you have Stateful workloads in the cluster.
- To increase upgrade speed, increase
maxUnavailableto only 1/3 of the number of desired instances. This number always keeps everything up and running. - Some DaemonSets, like kube-proxy and CNI plugin, may not work on the new Kubernetes version. You can upgrade them before upgrading the worker nodes. If pre-upgrading these components is not allowed, you must change the DaemonSet update strategy to
OnDeleteand update the manifest to the new version. So, the current nodes still run the old version, and new nodes will run the new version. I faced this situation when upgrading EKS 1.24 to 1.25 last year.
Conclusion:
Upgrading Kubernetes needs knowledge and hands-on experience. It requires an in-depth understanding of how Kubernetes works and a proper plan to upgrade. Always test everything in non-production environments first, and after fixing all possible issues, roll it out to production. If you need help to overcome your Kubernetes and EKS challenges, you can count on our Kubernetes experts at Kubedemy.
If you like this series of articles, please share them and write your thoughts as comments here. Your feedback encourages me to complete this massively planned program. Just share them and provide feedback. I’ll make you an AWS EKS black belt.
Follow my LinkedIn https://www.linkedin.com/in/ssbostan
Follow Kubedemy LinkedIn https://www.linkedin.com/company/kubedemy
Follow Kubedemy Telegram https://telegram.me/kubedemy
Related Posts
AWS EKS – Part 32 – Setup Cilium CNI on EKS Clusters
AWS EKS – Part 16 – Enable Secrets Encryption at Rest with AWS KMS Service